This post is also available in: English (英語) 简体中文 (簡体中国語) 繁體中文 (繁体中国語) 한국어 (韓国語) Português (ポルトガル語(ブラジル))
キプリング提唱のジャーナリズム原則がゼロトラスト ポリシー定義にどう役立つのか
ニュース記事やブログ投稿、ホワイトペーパーなどに信頼性を持たせたければ、その内容は「いつ、どこで、だれが、なにを、どうした」のか、つまり「5W1H」を網羅していなければなりません。でなければ、読者は説明の一部しか信頼することができないでしょう。小説家のRudyard Kipling(ラドヤード キップリング)はかつて、信頼にあたうジャーナリズムの本質を次のように明確に定義しています。
私には6人の忠実なしもべがいる。
(私が知るべきことはみな彼らが教えてくれる。)
その者たちの名は、What、Why、When、
そして How、Where、Who。-Rudyard Kipling『Just So Stories for Little Children』 1902年
この「Kiplingメソッド」は非常に有用で、ジャーナリズムのベスト プラクティスだけにとどまるものではありません。私は長年にわたり、このKiplingメソッドを活用して、企業がポリシーを定義し、ゼロトラスト ネットワークを構築できるように支援をしてきました。このメソッドを使えば、セキュリティ チームは定義すべきことをあまさず定義することができますし、アプローチがシンプルなので、技術力の高くないビジネス エグゼクティブにも、サイバーセキュリティ ポリシーを理解することができるようになります。ゼロトラストの第1設計原則はビジネス目標に重点を置くことですから、このメソッドは特に有用といえます。
レイヤー3ポリシーとレイヤー7ポリシーの比較
実際にKiplingメソッドを適用して本物のゼロトラスト アーキテクチャを構築するにあたり、まずは「ゼロトラスト アーキテクチャがなぜレイヤー3テクノロジでは実現できないのか」という理由を理解しておく必要があります。
それではレイヤー3とレイヤー7の違いとは何でしょうか。
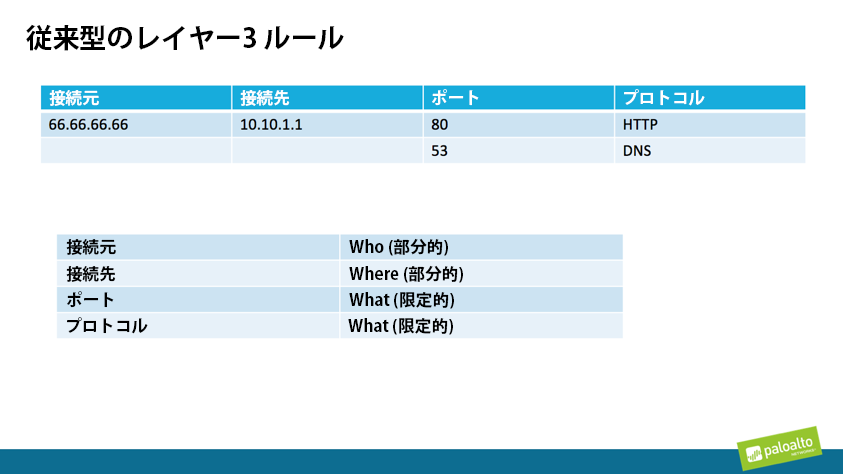
レイヤー3は、IPアドレス、ポート、またはプロトコルのみに基づいて情報が評価されるレイヤーです。これだけの情報しかないので、レイヤー3にできることはごく限られます。また、IPアドレスは偽装される可能性もありますし、オープンになっているポートはポートスキャンすればすべて検出できてしまうため、攻撃側は見つかったオープンポートを介して窃取したデータをカプセル化することが可能です。また「プロトコル」というのは単なるメタデータ タグであって、実際には、特定のポート上を流れることが想定されているトラフィックの種類を管理者が把握しやすくするための指標でしかありません。さらにいえば、すべての攻撃者がレイヤー3のセキュリティ対策をバイパスする方法を知っていますから、企業の安全性を確保したければ、より信頼性の高い方法で事物の定義ができねばなりません。
レイヤー7は、もっと具体的に、使用されている実際のアプリケーションに基づいて情報が評価されるレイヤーです。たとえば、「80番ポート上と443番ポート上を流れるトラフィック」という認識をするかわりに「Facebook」という固有のアプリケーション情報を認識するのです。
私は前職Forrester Research時代にゼロトラスト ネットワークに対する5ステップの方法論を作成しましたが、その4番目のステップとして「セグメンテーション ゲートウェイ用のポリシー ルールを作成するさいは、想定されるデータの振る舞いや、そのデータを操作するユーザーやアプリケーションの振る舞いに基づいて作成すること」と説明しています。こうしたポリシー ルールの作成は、ゼロトラスト環境のセグメンテーション ゲートウェイとして機能しうるパロアルトネットワークスの次世代ファイアウォールであれば実現可能です。というのも、セグメンテーション ゲートウェイではきめ細かくポリシーを設定せねばならないのでレイヤー7のもつ情報の認識が必要なのです。
パロアルトネットワークスの次世代ファイアウォールにKiplingメソッドを応用するには
それでは、パロアルトネットワークス次世代ファイアウォールの導入時、その革新的なUser-ID、App-ID、およびContent-IDテクノロジにKiplingメソッドを応用する方法について見ていきましょう。
- User-IDはKiplingメソッドのWHO文と考えることができます。すなわち「誰がリソースにアクセスしているのか」です。
User-IDは、送信元IPアドレスの情報をもとに、レイヤー7でより精度を高めてユーザー情報をインスタンス化したものです。たとえば、Active DirectoryからOUを取得し、そのドメインユーザーをカスタムUser-IDに紐付け、さらにGlobalProtectクライアントから多要素認証(MFA)やホスト情報プロファイル(HIP)を追加することで「誰がリソースにアクセスしているのか」すなわちWHO文の信頼性を高めることができます。さらにきめ細かく制御したければ、多要素認証をUser-IDと新たな属性に追加することもできます。
- App-IDはKiplingメソッドのWHAT文と考えることができます。すなわち「どのアプリケーションがリソースへのアクセスに使用されているか」です。
パロアルトネットワークスは本稿執筆時点で2,800種類以上App-IDを発行しています(日々追加されるアプリケーションの種類はApplipediaから確認可能)。これらApp-IDを活用してポリシー ルールを構築することにより、攻撃側は「Webサービス(HTTP/HTTPS)」といった汎用アプリケーション使用によるセキュリティ対策バイパスができなくなります。
- Content-IDはKiplingメソッドのHOW文と考えることができます。すなわち「どのような方法でUser-IDとApp-IDのトラフィックがリソースへのアクセスを許可されるべきか」です。
Content-IDには次のようなテクノロジが含まれます。
- 高度な侵入防御機能である Threat Preventionルール
- 悪意のあるトラフィックや窃取されたデータを暗号化したトンネル内に隠せないようにするSSL復号化
- ユーザーが悪意のあるドメインやフィッシング ドメインにアクセスしないようにするURL Filtering
- マルウェア活動を阻止する方法を再定義した最先端サンドボックステクノロジWildFire
- 自動化された保護に予測分析を適用し、DNSを使用した攻撃を阻止する弊社の新しいDNSセキュリティサービス
KiplingメソッドのWHO、WHAT、およびHOW文を定義するこれら3つのテクノロジを使用すれば、基本的なレイヤー7ルールの定義やその後のPanorama管理システムによるルール実装は容易になります。これにくわえてPAN-OSには、時間で表現するルールであるWHEN文、リソースの場所(多くの場合API経由で自動的にPanoramaに取り込み可能)で表現するWHERE文、データ分類ツールとルール内からメタデータを読み取ることによるWHY文を追加する機能もあります。
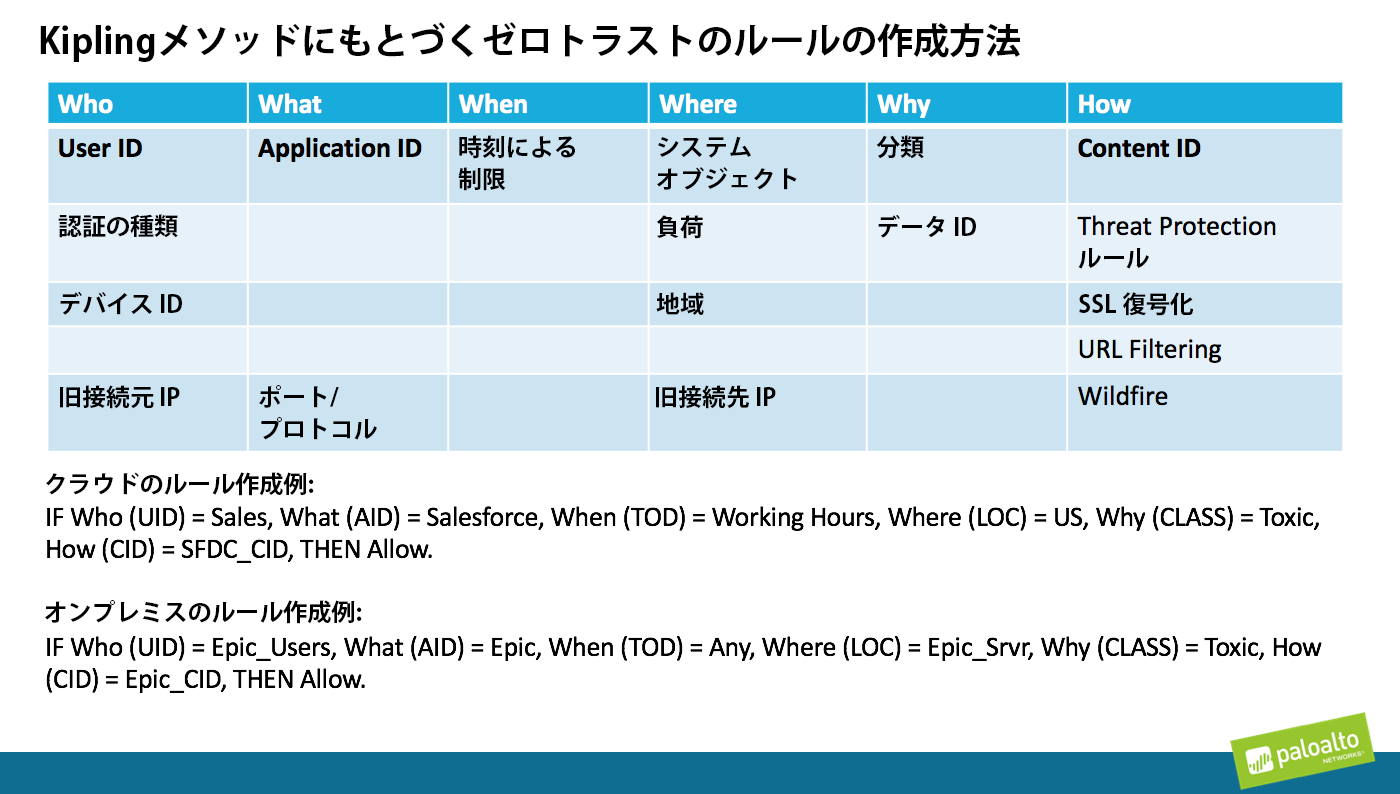
Kiplingメソッドは、ビジネスリーダーとセキュリティ管理者の両者がRudyard Kiplingの提唱した単純なWho、What、When、Where、Why、How手法を使用してきめ細かなレイヤー7ポリシーを定義できるように設計されたメソッドです。
ファイアウォールポリシーを作成したことのない方にも、このメソッドは容易に理解できますし、セグメンテーション ゲートウェイ用のルールセットを作成するさいに必要な基準を定義するときも、このメソッドはとても有用です。