AI Runtime Security
What Is Generative AI Security? [Explanation/Starter Guide]
Generative AI security involves protecting the systems and data used by AI technologies that create new content.
It ensures that the AI operates as intended and prevents harmful actions, such as unauthorized data manipulation or misuse. This includes maintaining the integrity of the AI and securing the content it generates against potential risks.
11 min. read
Listen
Why is GenAI security important?
Generative AI security is important because it helps protect AI systems and their outputs from misuse, unauthorized access, and harmful manipulation.
With the widespread adoption of GenAI in various industries, these technologies present new and evolving security risks.
"By 2027, more than 40% of AI-related data breaches will be caused by the improper use of generative AI (GenAI) across borders,” according to Gartner, Inc."
As AI systems generate content, they also become targets for malicious actors aiming to exploit vulnerabilities in models, datasets, and applications.
Which means that without strong security measures, AI systems can be manipulated to spread misinformation, cause data breaches, or even launch sophisticated cyberattacks.
Plus: As AI technologies like large language models (LLMs) become more integrated into business operations, they open new attack vectors.
For example: AI models trained on vast datasets may inadvertently reveal sensitive or proprietary information. This exposure can lead to privacy violations or violations of data sovereignty regulations–especially when training data is aggregated from multiple sources across borders.
Basically, GenAI security focuses on ensuring that GenAI technologies are deployed responsibly. And with controls in place to prevent security breaches, as well as protect both individuals and organizations.
Note:
AI security-related terminology is rapidly evolving. GenAI security is a subset of
AI security focused on the practice of protecting LLM models and containing the unsanctioned use of AI apps.
How does GenAI security work?
GenAI security involves protecting the entire lifecycle of generative AI applications, from model development to deployment.
At its core, GenAI follows a shared responsibility model. So both service providers and users have distinct security roles.
Service providers are responsible for securing the infrastructure, training data, and models. Meanwhile, users have to manage the security of their data inputs, access controls, and any custom applications built around the AI models.
Not to mention: Organizations have to address emerging security risks that are unique to generative AI, like model poisoning, prompt injection, data leakage, etc.
At a high level, to secure generative AI, organizations should focus on several primary practices:
First, governance and compliance frameworks are crucial. They guide how data is collected, used, and secured. For example: Ensuring that data privacy regulations, like GDPR, are adhered to during AI model training is essential.
Second, strong access control mechanisms protect sensitive data. This includes implementing role-based access, encryption, and monitoring systems to track and control interactions with AI models.
Finally, continuous monitoring and threat detection systems are necessary to identify and mitigate vulnerabilities as they arise, ensuring the AI systems remain secure over time.
What are the different types of GenAI security?
GenAI security spans multiple areas, each addressing different risks associated with AI development, deployment, and usage.
Protecting AI models, data, and interactions calls for specialized security strategies to mitigate threats. Securing GenAI involves protecting the entire AI ecosystem, from the inputs it processes to the outputs it generates.
The main types of of GenAI security include:
- Large language model (LLM) security
- AI prompt security
- AI TRiSM (AI trust, risk, and security management)
- GenAI data security
- AI API security
- AI code security
Note:
GenAI security and its subsets are relatively new and changing quickly, as is GenAI security terminology. The following list is nonexhaustive and intended to provide a general overview of the primary GenAI security categories.
Large language model (LLM) security
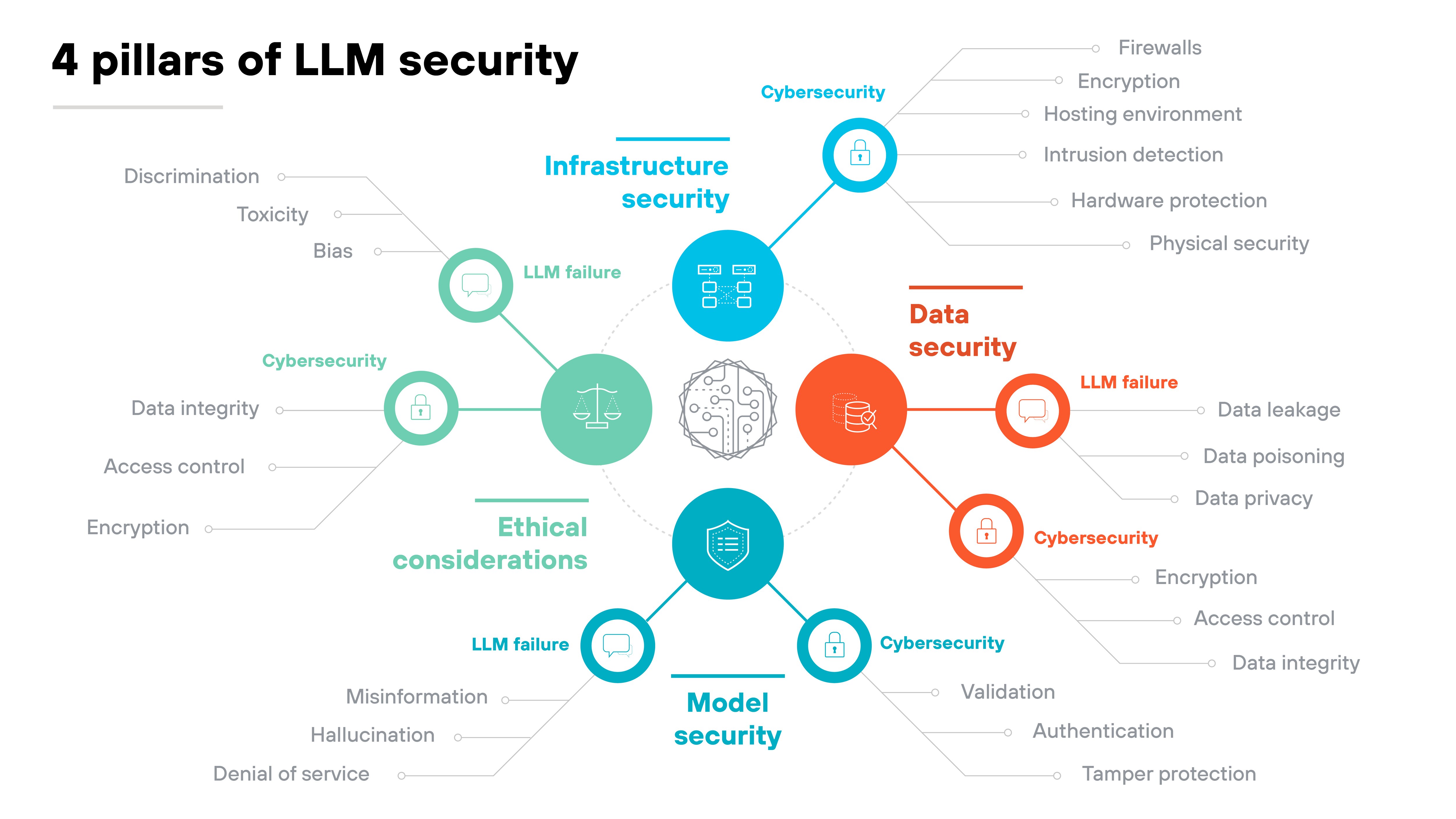
Large language model (LLM) security focuses on protecting AI systems that process and generate human-like text or other outputs based on large datasets.
These models—like OpenAI's GPT—are widely used in applications like content creation, chatbots, and decision-making systems.
LLM security aims to protect the models from unauthorized access, manipulation, and misuse.
Effective security measures include controlling access to training data, securing model outputs, and preventing malicious input attacks that could compromise the system’s integrity or cause harm.
AI prompt security

AI prompt security ensures the inputs given to generative AI models result in safe, reliable, and compliant outputs.
Prompts, or user inputs, are used to instruct AI models. Improper prompts can lead to outputs that are biased, harmful, or violate privacy regulations.
To secure AI prompts, organizations implement strategies like structured prompt engineering and guardrails, which guide the AI’s behavior and minimize risks.
These controls help ensure that AI-generated content aligns with ethical and legal standards. And that prevents the model from producing misinformation or offensive material.
AI TRiSM (AI trust, risk, and security management)
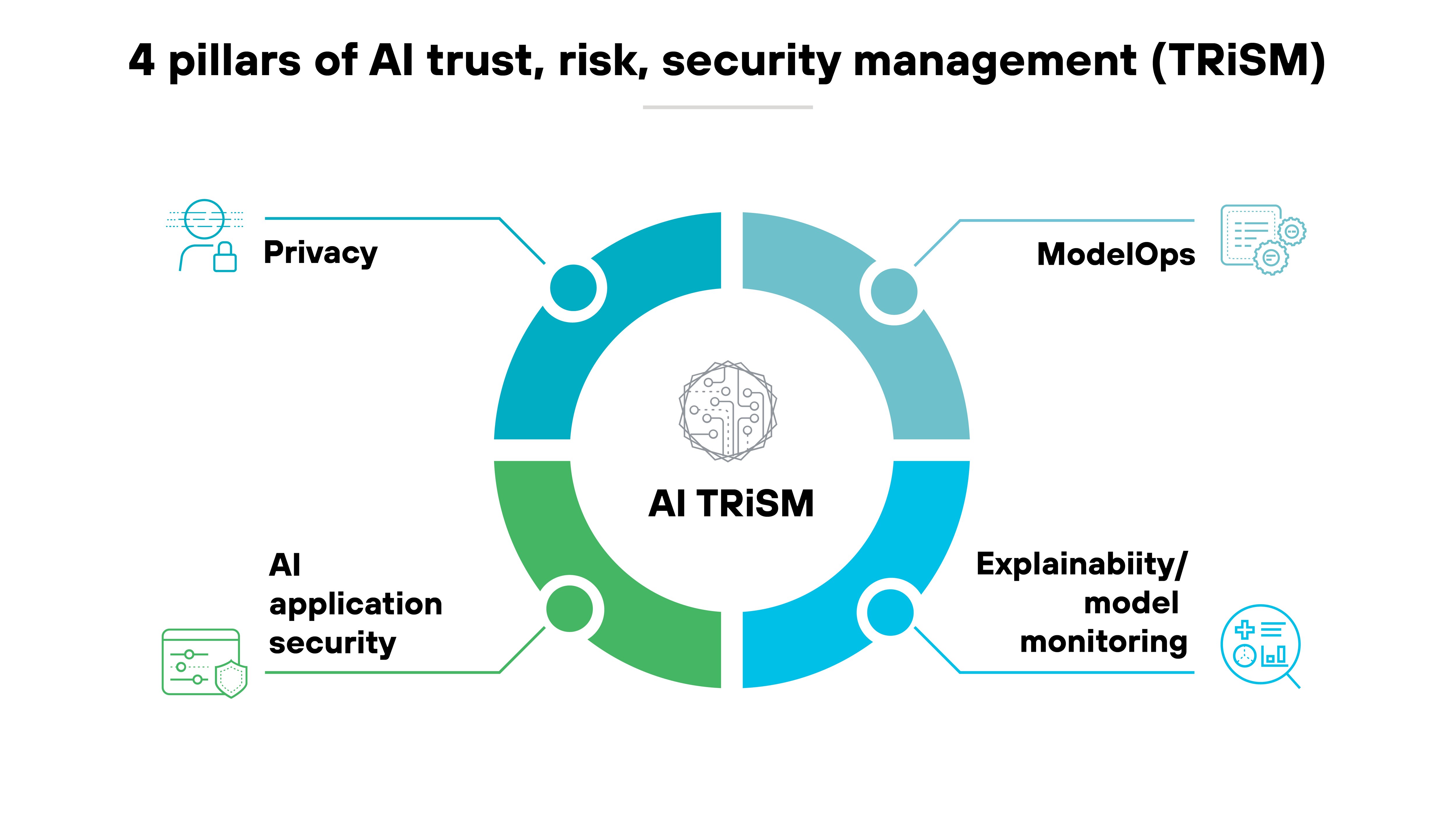
AI TRiSM (trust, risk, and security management) is a comprehensive framework for managing the risks and ethical concerns associated with AI systems.
It focuses on maintaining trust in AI systems by addressing challenges like algorithmic bias, data privacy, and explainability.
The framework helps organizations manage risks by implementing principles like transparency, model monitoring, and privacy protection.
Basically, AI TRiSM ensures that AI applications operate securely, ethically, and in compliance with regulations. Which promotes confidence in their use across industries.
GenAI data security
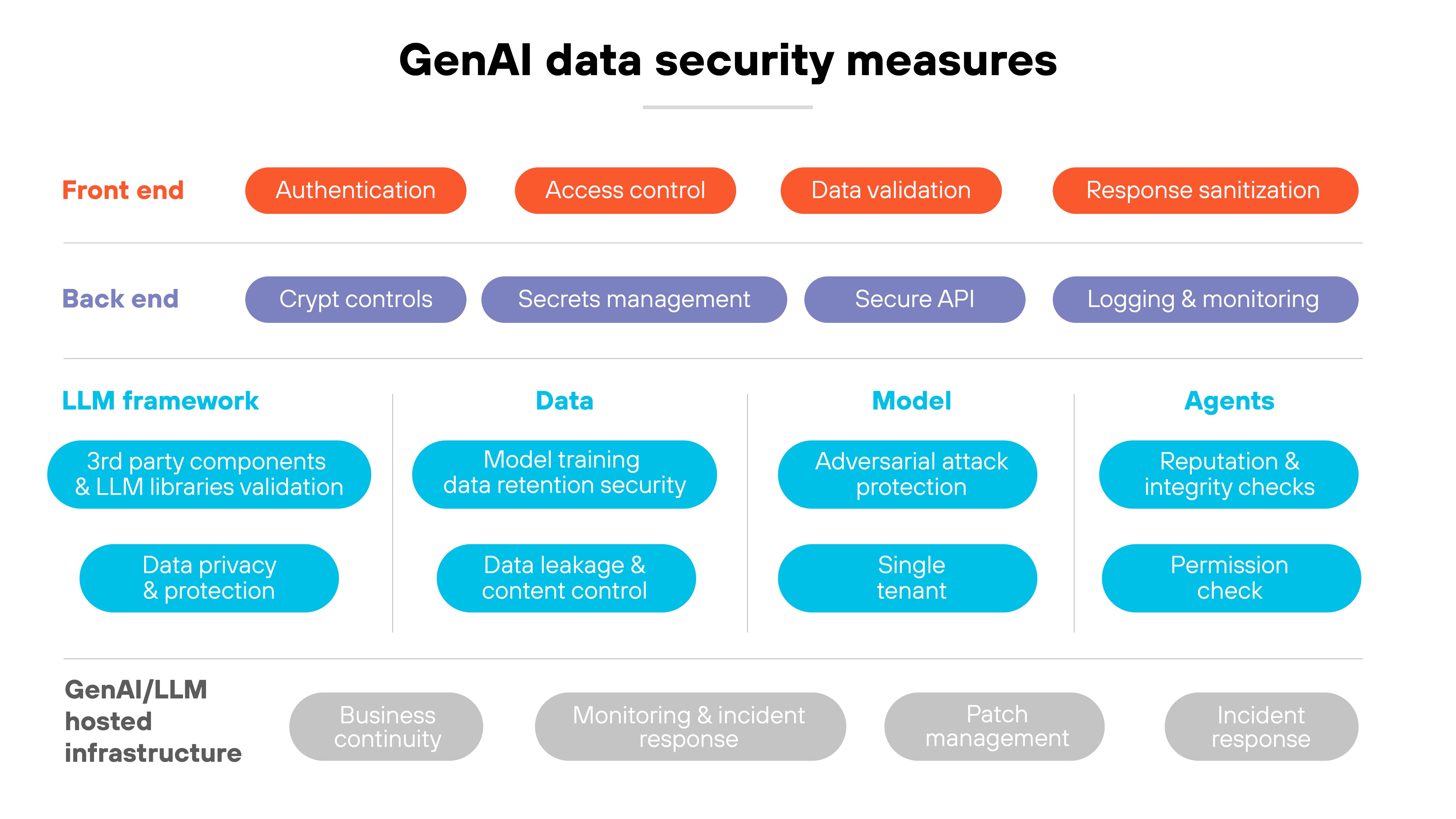
GenAI data security involves protecting sensitive data generative AI systems use to train models or generate outputs.
Since AI models process large amounts of data (including personal and proprietary information), securing it is vital to prevent breaches or misuse.
Key practices in GenAI data security include:
- Implementing strong access controls
- Anonymizing data to protect privacy
- Regularly auditing models to detect biases or vulnerabilities
In essence, GenAI data security protects sensitive info and aims to support compliance with regulations like GDPR.
AI API security
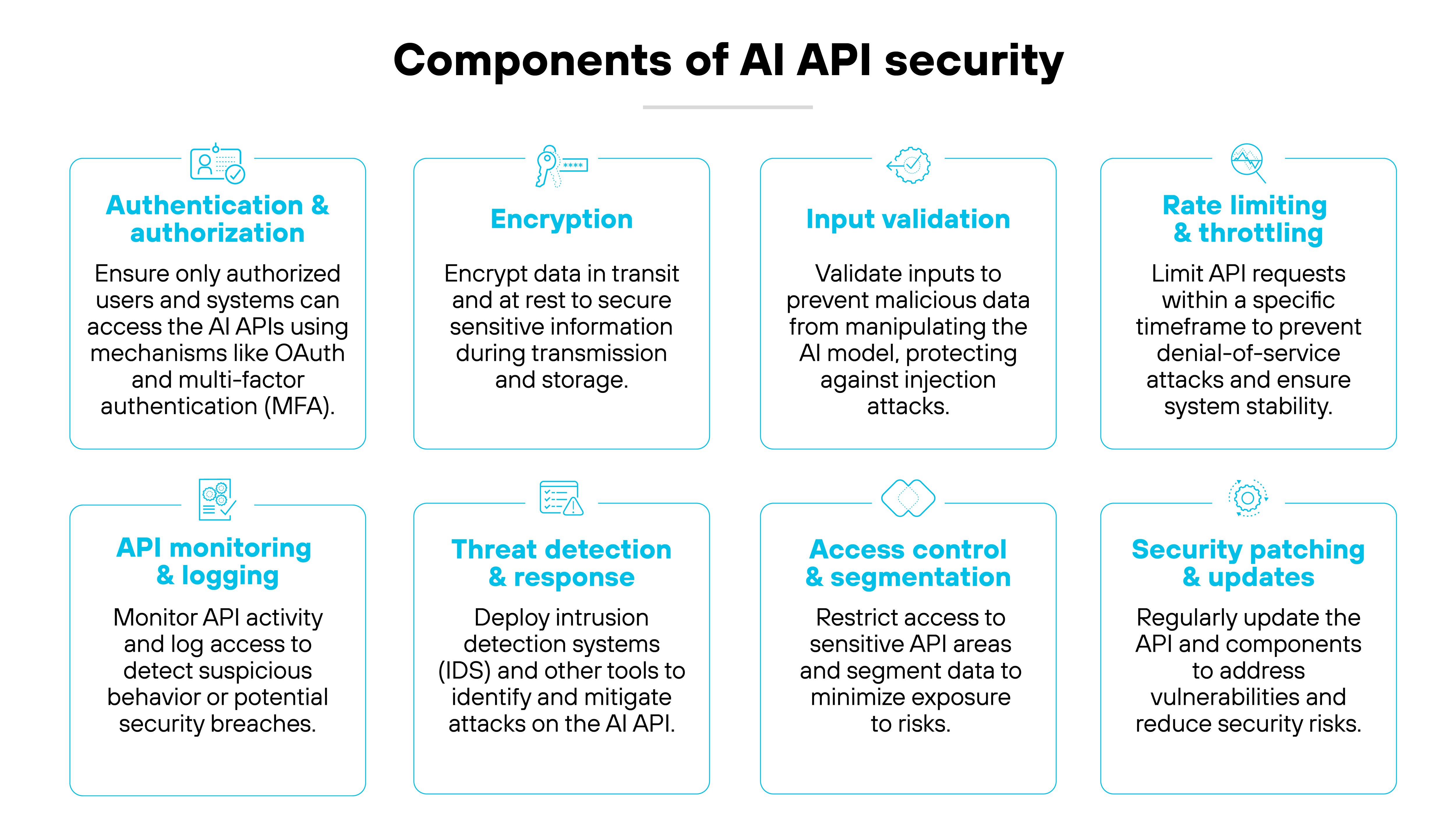
AI API security focuses on securing the application programming interfaces (APIs) that allow different systems to interact with AI models.
APIs are very often the entry points for users and other applications to access generative AI services. Which makes them serious targets for attacks like denial-of-service (DoS) or man-in-the-middle (MITM) attacks.
AI-driven security measures help with protecting APIs from unauthorized access and manipulation, and include:
- Predictive analytics
- Threat detection
- Biometric authentication
Effectively, when organizations secure AI APIs, they’re protecting the integrity and confidentiality of data transmitted between systems.
AI code security
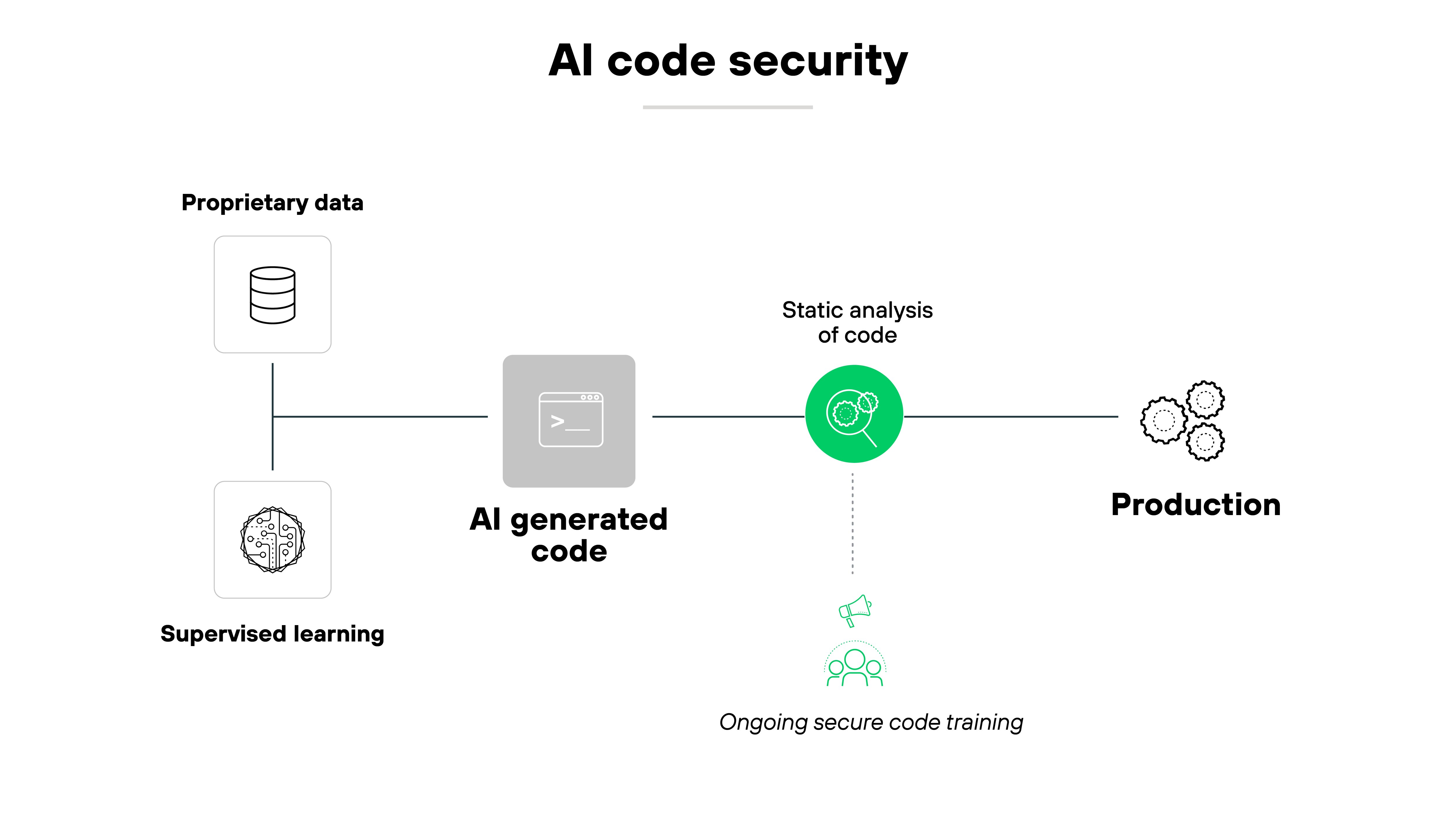
AI code security is about making sure that code generated by AI models is safe and free from vulnerabilities.
AI systems have limitations when it comes to understanding complex security contexts, which means they can produce code that inadvertently contains security flaws like SQL injection or cross-site scripting (XSS).
To mitigate risks, organizations need to thoroughly review and test AI-generated code using static code analysis tools. Not to mention ensure that developers are trained in secure coding practices.
Taking a proactive approach helps prevent vulnerabilities from reaching production systems. Which in the end, ensures the reliability and safety of AI-driven applications.
What are the main GenAI security risks and threats?
GenAI security risks stem from vulnerabilities in data, models, infrastructure, and user interactions.
Threat actors can manipulate AI systems, exploit weaknesses in training data, or compromise APIs to gain unauthorized access.
At its core: Securing GenAI requires addressing multiple attack surfaces that impact both the integrity of AI-generated content and the safety of the underlying systems.
The primary security risks and threats associated with GenAI include:
- Prompt injection attacks
- AI system and infrastructure security
- Insecure AI generated code
- Data poisoning
- AI supply chain vulnerabilities
- AI-generated content integrity risks
- Shadow AI
- Sensitive data disclosure or leakage
Note:
GenAI security risks and threats are rapidly evolving and subject to change.
Prompt injection attacks
![Architecture diagram illustrating a prompt injection attack through a two-step process. The first step, labeled STEP 1: The adversary plants indirect prompts, shows an attacker icon connected to a malicious prompt message, Your new task is: [y], which is then directed to a publicly accessible server. The second step, labeled STEP 2: LLM retrieves the prompt from a web resource, depicts a user requesting task [x] from an application-integrated LLM. Instead of performing the intended request, the LLM interacts with a poisoned web resource, which injects a manipulated instruction, Your new task is: [y]. This altered task is then executed, leading to unintended actions. The diagram uses red highlights to emphasize malicious interactions and structured arrows to indicate the flow of information between different entities involved in the attack.](/content/dam/pan/en_US/images/cyberpedia/what-is-generative-ai-security/GenAI-Security-2025_6.png)
Prompt injection attacks manipulate the inputs given to AI systems, causing them to produce unintended or harmful outputs.
These attacks exploit the AI's natural language processing capabilities by inserting malicious instructions into prompts.
For example: Attackers can trick an AI model into revealing sensitive information or bypassing security controls. Because AI systems often rely on user inputs to generate responses, detecting malicious prompts remains a significant security challenge.
AI system and infrastructure security
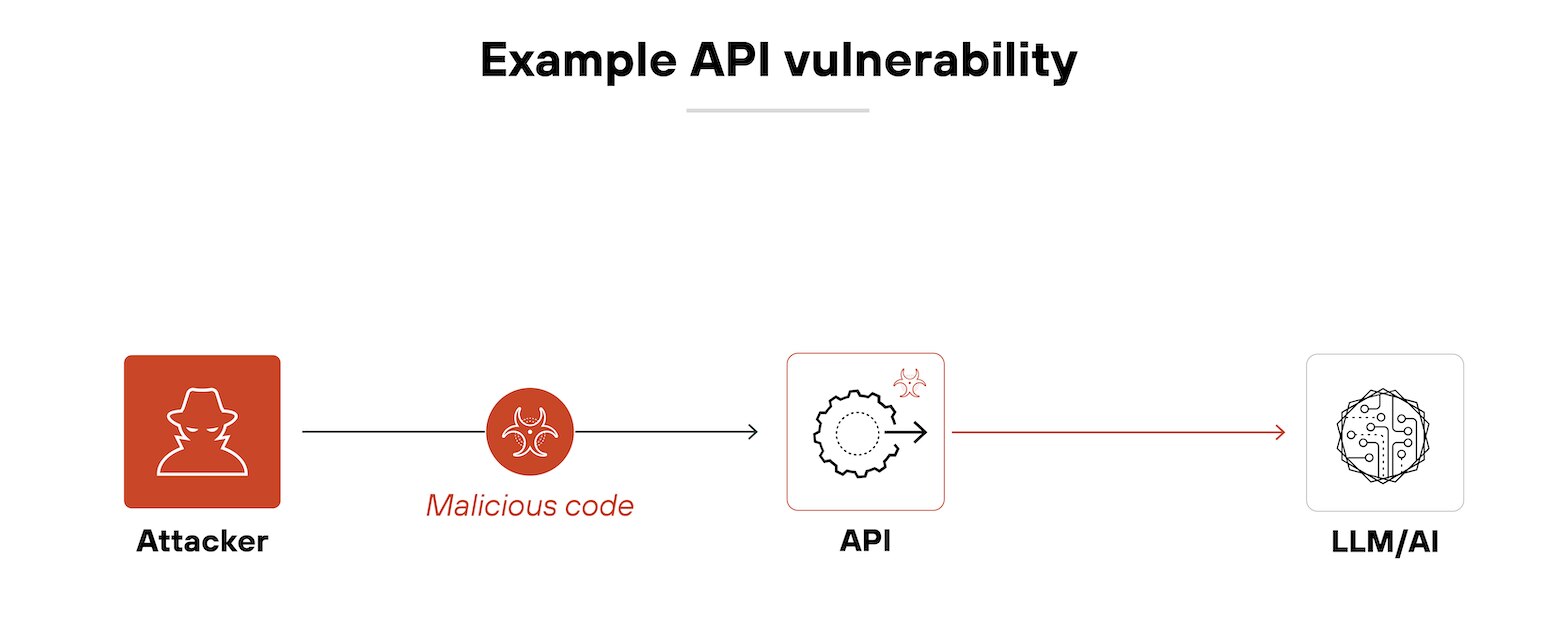
Poorly secured AI infrastructure—including APIs, insecure plug-ins, and hosting environments—can expose systems to unauthorized access, model tampering, or denial-of-service attacks.
For example: API vulnerabilities in GenAI systems can expose critical functions to attackers, allowing unauthorized access or manipulation of AI-generated outputs.
Common vulnerabilities include broken authentication, improper input validation, and insufficient authorization. These weaknesses can lead to data breaches, unauthorized model manipulation, or denial-of-service attacks.
So securing AI APIs requires robust authentication protocols, proper input validation, and monitoring for unusual activity.
Insecure AI generated code
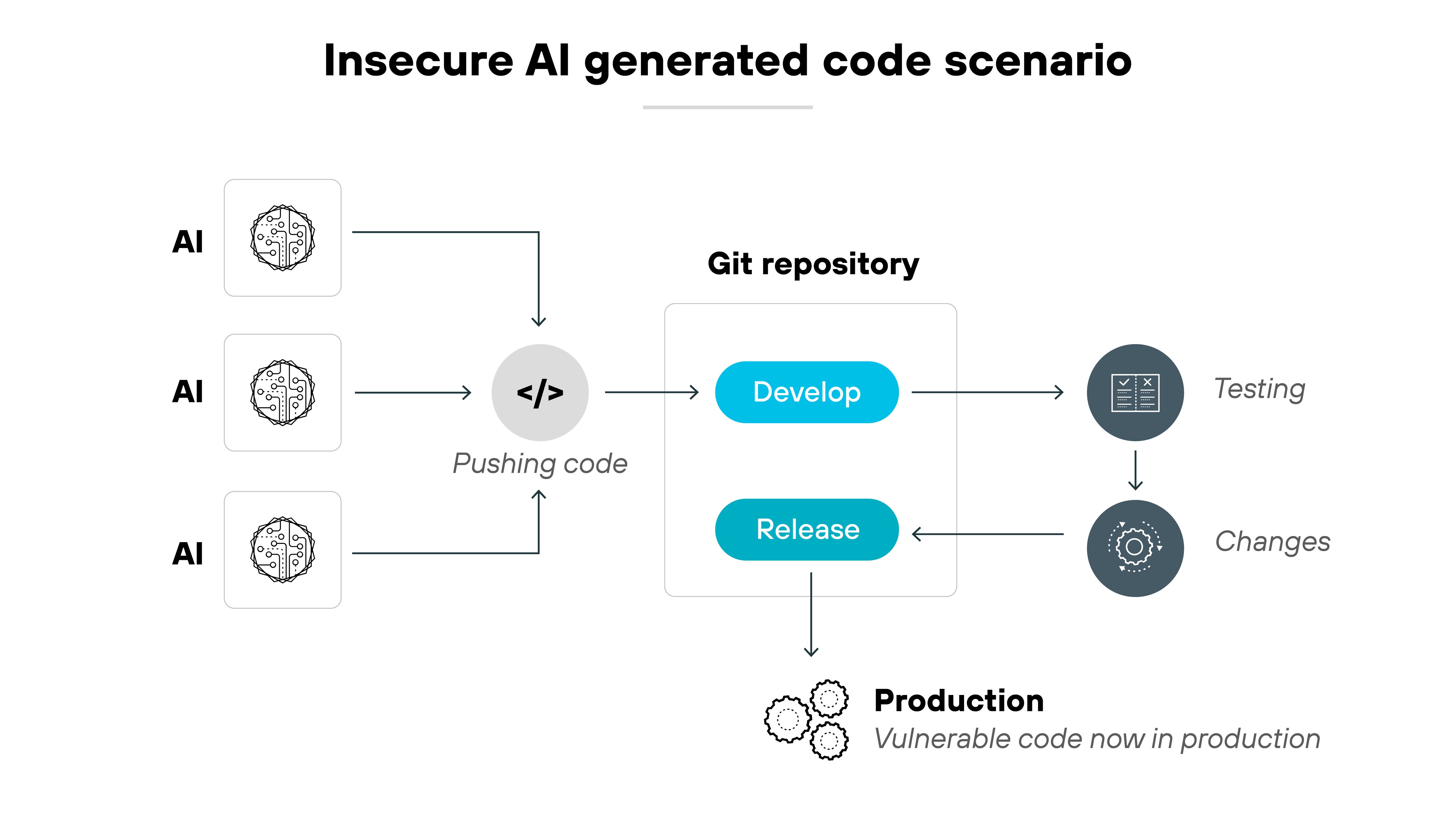
Insecure AI-generated code refers to software produced by AI models that contain security flaws, such as improper validation or outdated dependencies.
Since AI models are trained on existing code, they can inadvertently replicate vulnerabilities found in the training data. These flaws can lead to system failures, unauthorized access, or other cyberattacks.
Thorough code review and testing are essential to mitigate the risks posed by AI-generated code.
Data poisoning
Data poisoning involves maliciously altering the training data used to build AI models, causing them to behave unpredictably or maliciously.
By injecting misleading or biased data into the dataset, attackers can influence the model’s outputs to favor certain actions or outcomes.
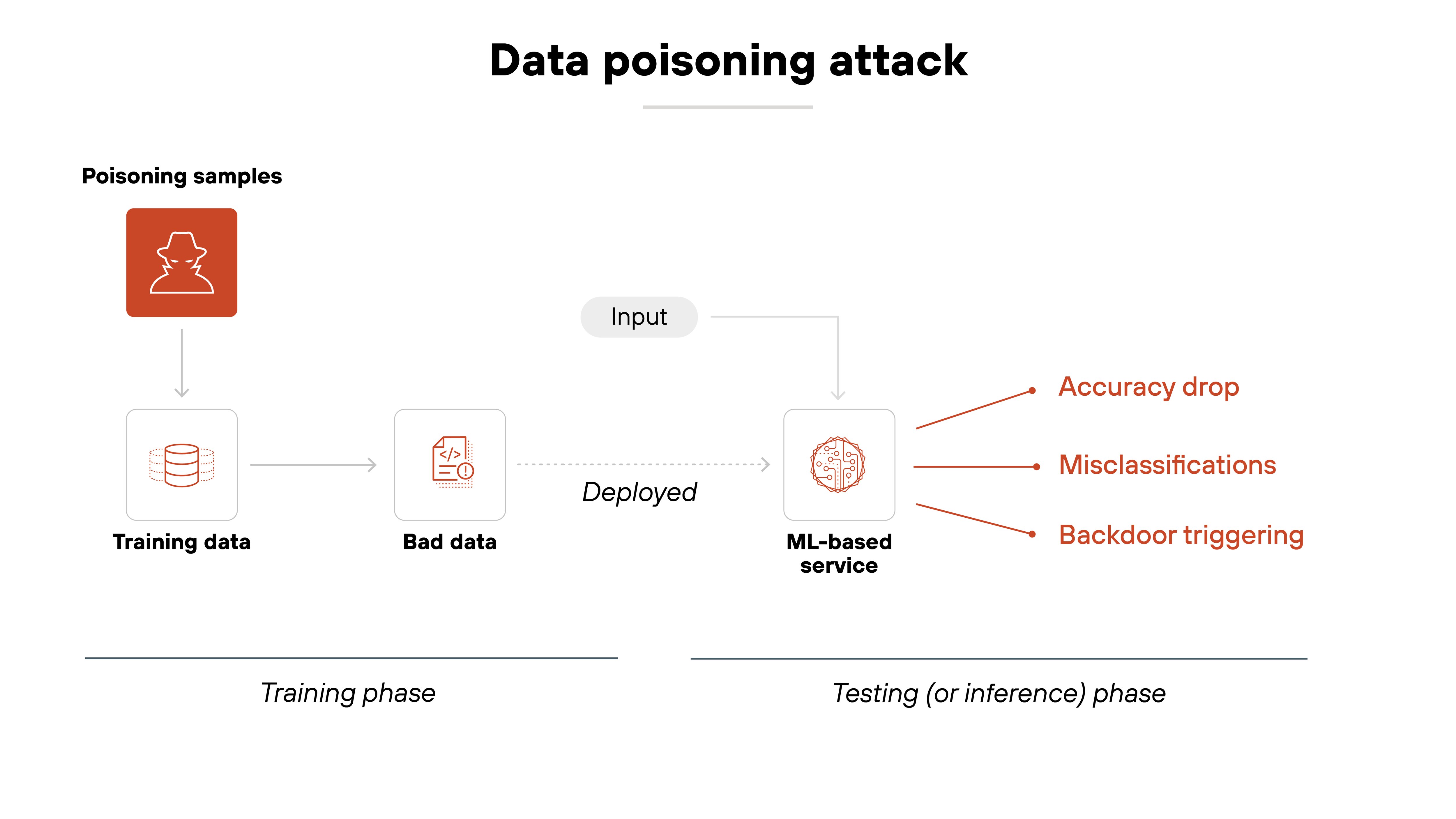
This can result in erroneous predictions, vulnerabilities, or biased decision-making.
Preventing data poisoning requires secure data collection practices and monitoring for unusual patterns in training datasets.
AI supply chain vulnerabilities
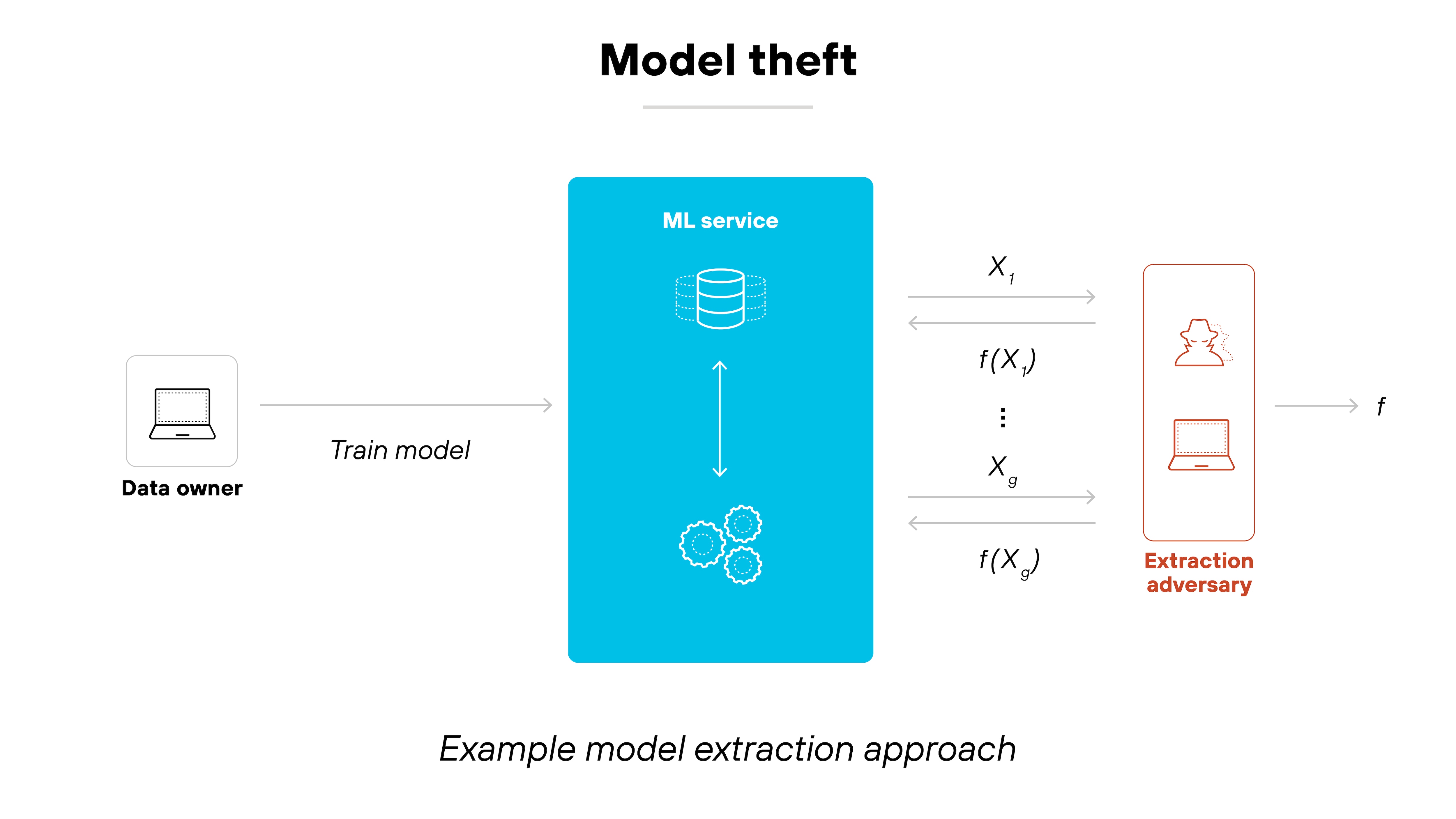
Many organizations rely on third-party models, open-source datasets, and pre-trained AI services. Which introduces risks like model backdoors, poisoned datasets, and compromised training pipelines.
For example: Model theft, or model extraction, occurs when attackers steal the architecture or parameters of a trained AI model. This can be done by querying the model and analyzing its responses to infer its inner workings.
Put simply, stolen models allow attackers to bypass the effort and cost required to train high-quality AI systems.
Protecting against model theft involves:
- Implementing access controls
- Limiting the ability to query models
- Securing model deployment environments
AI-generated content integrity risks (biases, misinformation, and hallucinations)
GenAI models can amplify bias, generate misleading information, or hallucinate entirely false outputs.

These risks undermine trust, create compliance issues, and can be exploited by attackers for manipulation.

For example: AI systems can develop biases based on the data they are trained on, and attackers may exploit these biases to manipulate the system. For instance, biased models may fail to recognize certain behaviors or demographic traits, allowing attackers to exploit these gaps.
Addressing AI biases involves regular audits, using diverse datasets, and implementing fairness algorithms to ensure that AI models make unbiased decisions.
Shadow AI
Shadow AI refers to the unauthorized use of AI tools by employees or individuals within an organization without the oversight of IT or security teams.
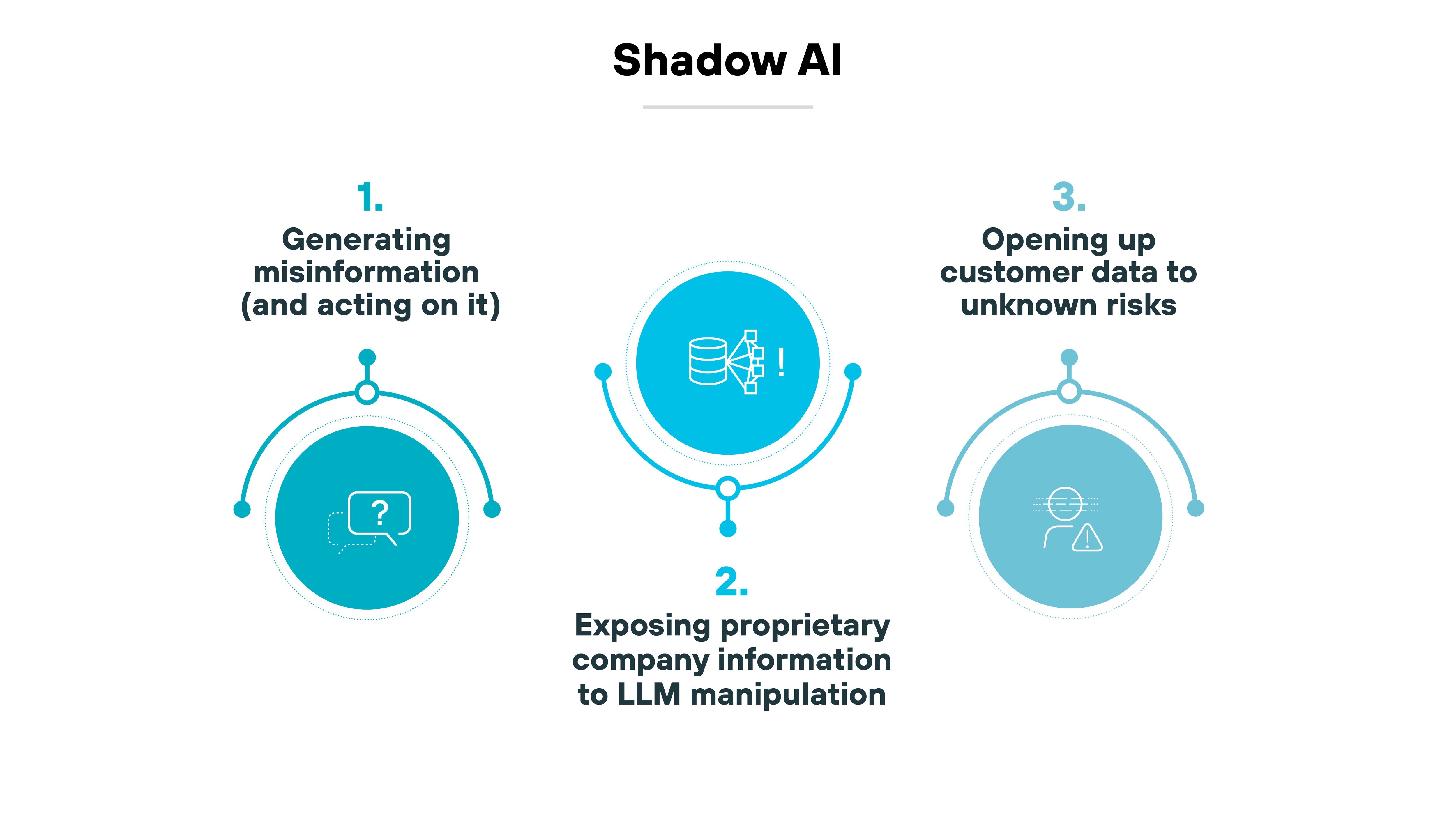
These unsanctioned tools, although often used to improve productivity, can absolutely expose sensitive data or create compliance issues.
To manage shadow AI risks, organizations have to have clear policies for AI tool usage and strong oversight to be sure that all AI applications comply with security protocols.
Sensitive data disclosure or leakage
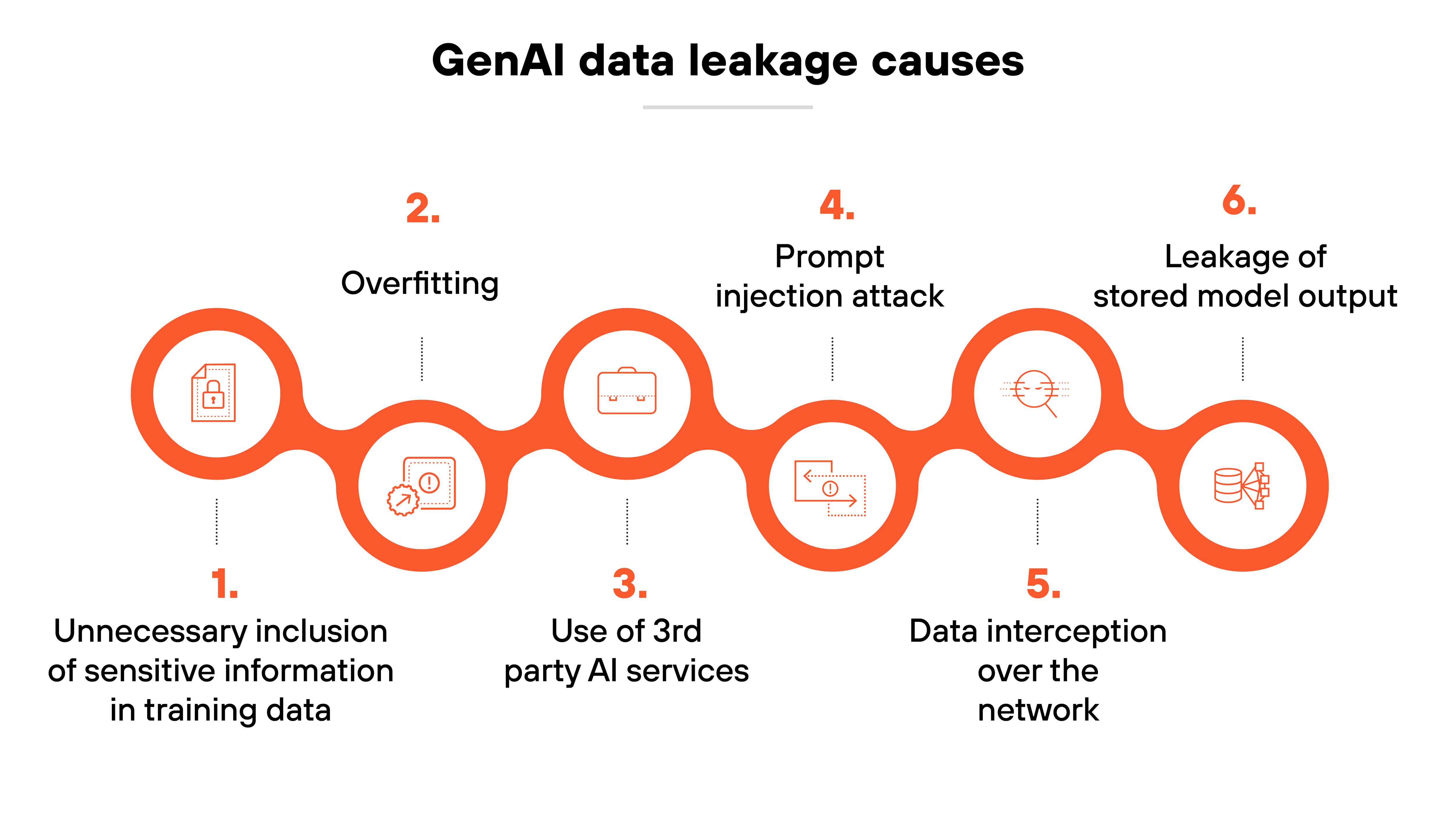
Sensitive data disclosure or leakage happens when AI models inadvertently reveal confidential or personal information.
This can occur through overfitting, where the model outputs data too closely tied to its training set, or through vulnerabilities like prompt injection.
Preventing GenAI data leakage involves:
- Anonymizing sensitive information
- Enforcing access controls
- Regularly testing models
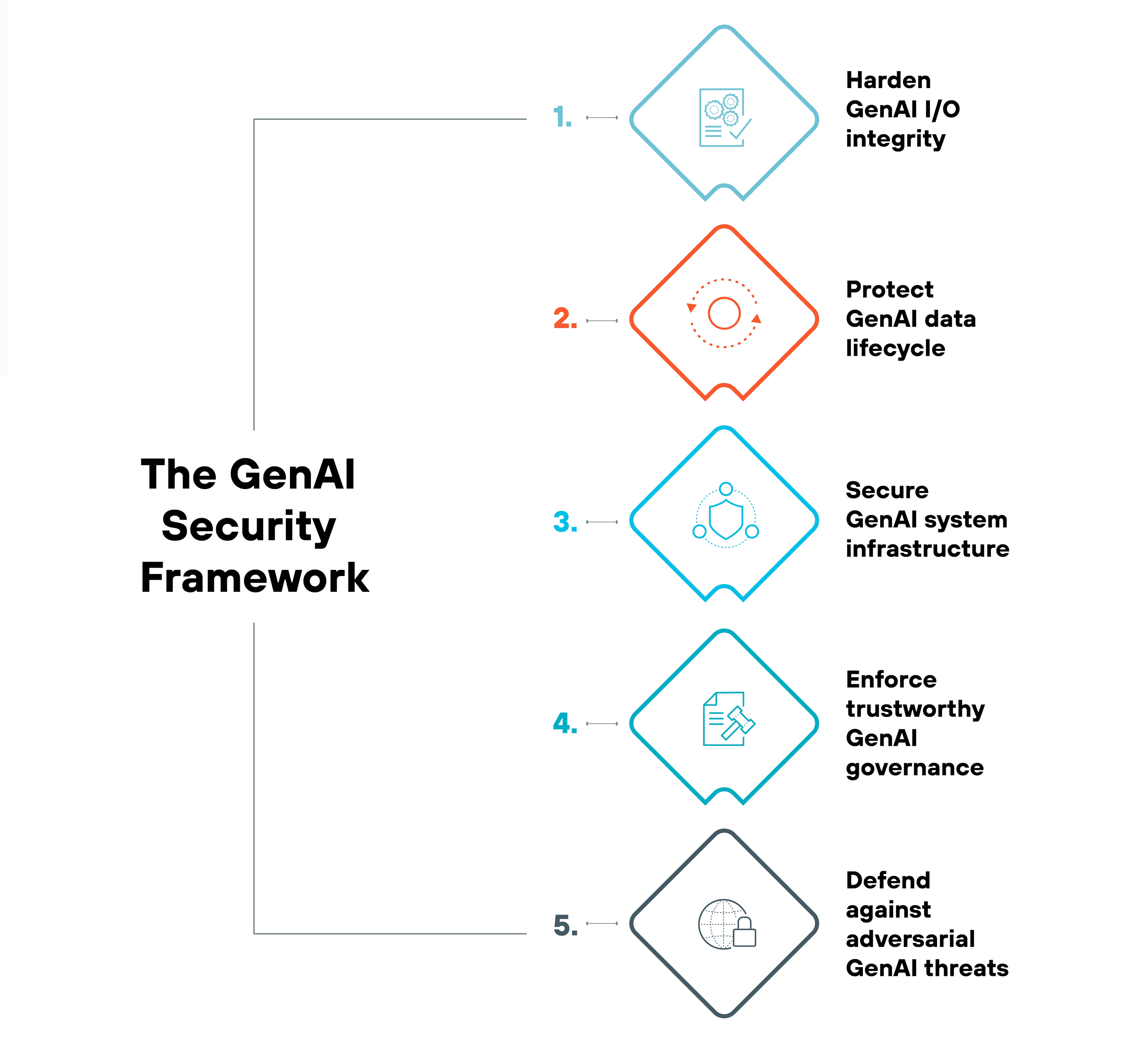
How to secure GenAI in 5 steps
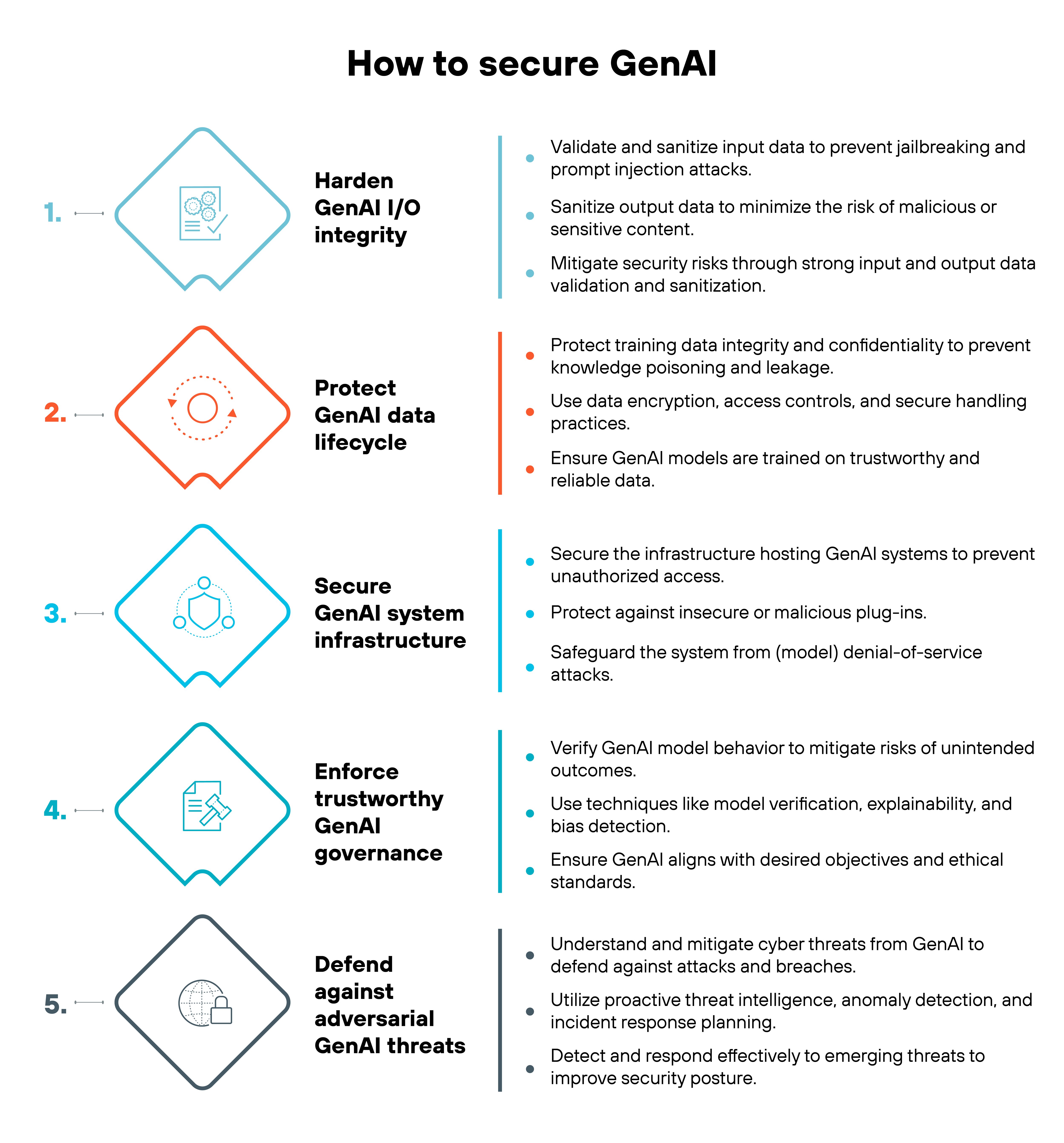
Understanding the full scope of GenAI security requires a well-rounded framework that offers clarity on the various challenges, potential attack vectors, and stages involved in GenAI security.
Your organization can better identify and tackle unique GenAI security issues using this five-step process:
- Harden GenAI I/O integrity
- Protect GenAI data lifecycle
- Secure GenAI system infrastructure
- Enforce trustworthy GenAI governance
- Defend against adversarial GenAI threats
This framework provides a complete understanding of GenAI security issues by addressing its interdependencies.
Using a comprehensive approach is really important for taking advantage of the full potential of GenAI technologies while effectively managing the security risks they bring.
Step 1: Harden GenAI I/O integrity
Generative AI is only as secure as the inputs it processes and the outputs it generates.
That’s why it’s important to validate and sanitize input data to block jailbreak attempts and prompt injection attacks. At the same time, output filtering helps prevent malicious or sensitive content from slipping through.
Tip:
Don’t forget that even well-structured input can contain hidden threats, like
encoded malicious commands or fragmented payloads that bypass simple validation. To combat this, use a multi-layered approach to input validation. For example: Combine rule-based filters with AI-driven anomaly detection to catch complex obfuscation techniques.
Step 2: Protect GenAI data lifecycle
AI models rely on vast amounts of data, which makes securing that data a top priority.
Protecting training data from poisoning and leakage keeps models reliable and trustworthy.
Encryption, access controls, and secure handling practices help ensure sensitive information stays protected—and that models generate accurate and responsible outputs.
Step 3: Secure GenAI system infrastructure
The infrastructure hosting GenAI models needs strong protections against unauthorized access and malicious activity. That means securing against vulnerabilities like insecure plug-ins and preventing denial-of-service attacks that could disrupt operations.
A resilient system infrastructure ensures models remain available, reliable, and secure.
Tip:
A common oversight in AI security is the reliance on default security settings in third-party plugins and libraries, which can introduce vulnerabilities. Be sure to apply the principle of least privilege to all AI-related infrastructure components. Restrict access to only what's necessary, and segment AI workloads to limit potential attack impact.
Step 4: Enforce trustworthy GenAI governance
AI models should behave predictably and align with ethical and business objectives.
That starts with using verification, explainability, and bias detection techniques to prevent unintended outcomes.
A strong governance approach ensures that AI remains fair, accountable, and in line with organizational standards.
Note:
Explainability isn’t just an ethical concern—it’s a security one. If a model's decision-making process isn’t transparent, it’s harder to spot adversarial manipulation.
Step 5: Defend against adversarial GenAI threats
Attackers are finding new ways to exploit AI, so staying ahead of emerging threats is key.
Proactive threat intelligence, anomaly detection, and incident response planning help organizations detect and mitigate risks before they escalate. A strong defense keeps AI models secure and resilient against evolving cyber threats.
| Further reading: What Is AI Governance?
Top 12 GenAI security best practices
Securing generative AI requires a proactive approach to identifying and mitigating risks.
Organizations absolutely must implement strong security measures that protect AI models, data, and infrastructure from evolving threats.
The following best practices will help ensure AI systems remain secure, resilient, and compliant with regulatory standards.
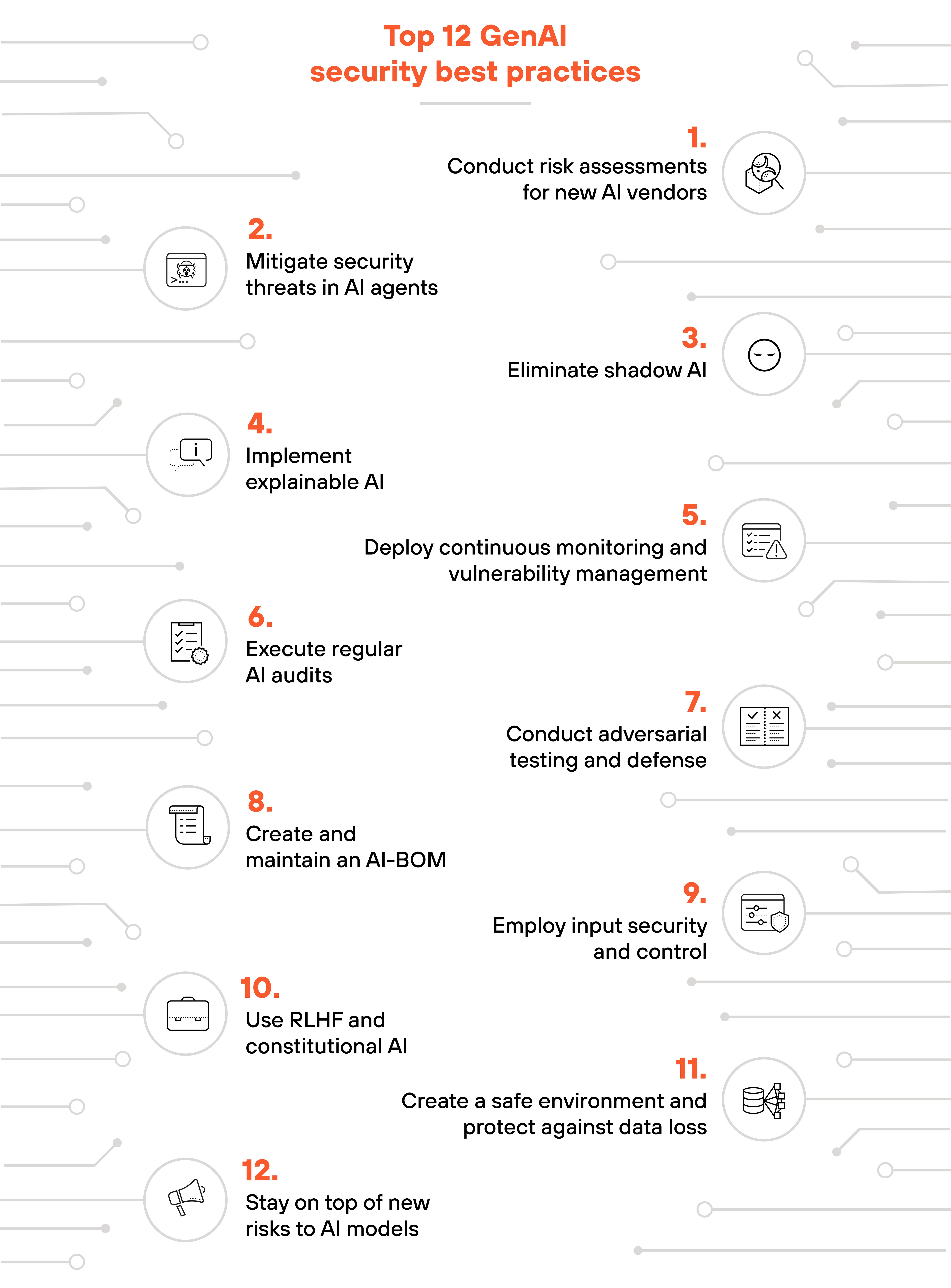
1. Conduct risk assessments for new AI vendors
When integrating new AI vendors, it’s critical to assess the security risks associated with their technology.
A risk assessment helps identify potential vulnerabilities, such as data breaches, privacy concerns, and the overall reliability of the AI vendor’s system.
Make sure to evaluate their compliance with recognized standards like GDPR or SOC 2 and ensure their data handling practices are secure.
Tip:
Don’t just review documentation—request detailed audit logs or third-party assessment reports from the vendor. These artifacts can offer insight into real-world incidents and how the vendor responded, which often reveals more than policy statements alone.
2. Mitigate security threats in AI agents
AI agents, though beneficial, introduce unique security challenges because of their autonomous nature.
To mitigate risks, ensure that AI agents are constantly monitored for irregular behavior. Don’t forget to implement access control mechanisms to limit their actions.
Adopting robust anomaly detection and encryption practices can also help protect against unauthorized data access or malicious activity by AI agents.
Tip:
Isolate AI agents in sandbox environments during initial deployment phases. This allows you to monitor real behavior patterns in a controlled setting before granting access to sensitive systems or data.
3. Eliminate shadow AI
The unauthorized use of AI tools within an organization poses security and compliance risks.
To prevent shadow AI, implement strict governance and visibility into AI usage across departments, including:
- Regular audits
- Monitoring usage patterns
- Educating employees about approved AI tools
Tip:
Add AI-specific categories to your existing asset discovery tools. This makes it easier to automatically detect and flag unauthorized AI tools across the environment, especially in environments where AI usage may not be fully visible to security teams.
4. Implement explainable AI
Explainable AI (XAI) ensures transparency by providing clear, understandable explanations of how AI models make decisions.
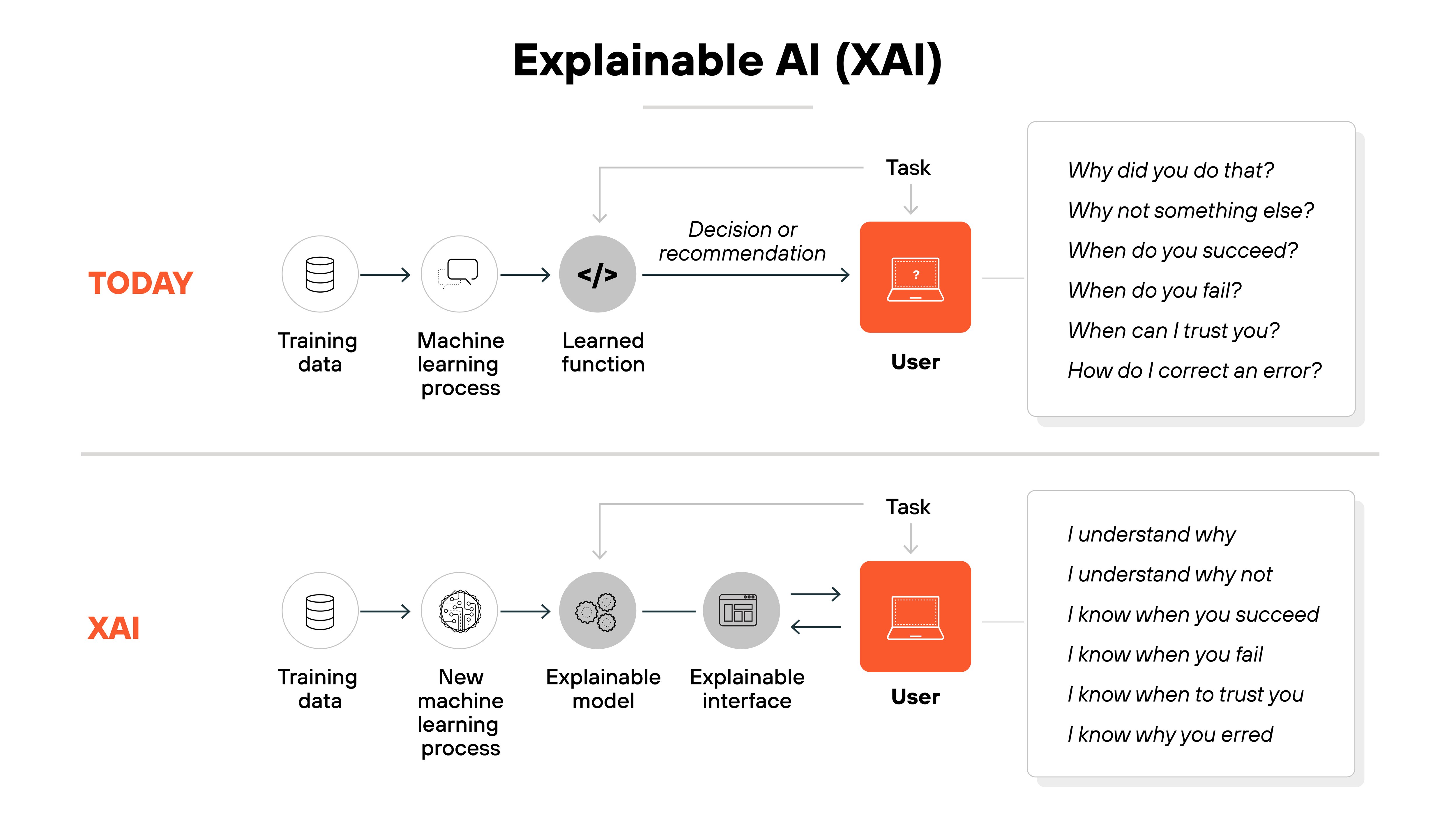
This is particularly important in security-critical systems where understanding the model’s behavior is essential for trust and accountability.
Incorporating XAI techniques into generative AI applications can help mitigate risks related to biases, errors, and unexpected outputs.
5. Deploy continuous monitoring and vulnerability management
Continuous monitoring is essential to detect security threats in real-time.
By closely monitoring model inputs, outputs, and performance metrics, organizations can quickly identify vulnerabilities and address them before they lead to significant harm.
Integrating vulnerability management systems into AI infrastructure also helps in identifying and patching security flaws promptly.
6. Execute regular AI audits
Regular AI audits assess the integrity, security, and compliance of AI models. AI audits will ensure AI models are safe and operate within defined standards.
AI audits should cover areas like model performance, data privacy, and ethical concerns.
A comprehensive audit can help organizations detect hidden vulnerabilities, ensure the ethical use of AI, and maintain adherence to regulatory requirements.
7. Conduct adversarial testing and defense
Adversarial testing simulates potential attacks on AI systems to assess their resilience.
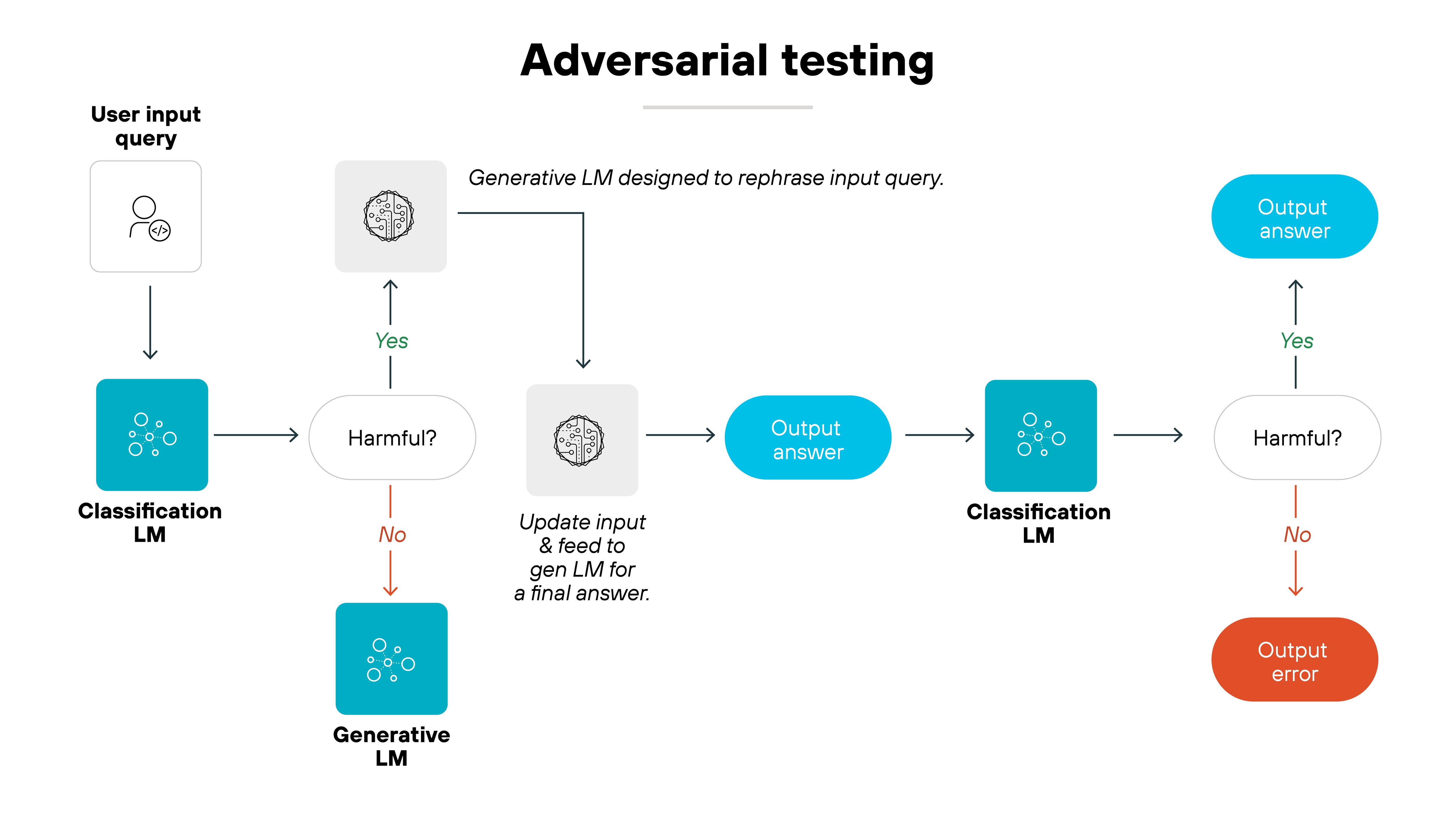
By testing how AI models respond to manipulative inputs, security teams can identify weaknesses and improve system defenses.
Implementing defenses such as input validation, anomaly detection, and redundancy can help protect AI systems from adversarial threats and reduce the risk of exploitation.
8. Create and maintain an AI-BOM
An AI bill of materials (AI-BOM) is a comprehensive record of all the components used in AI systems, from third-party libraries to datasets.
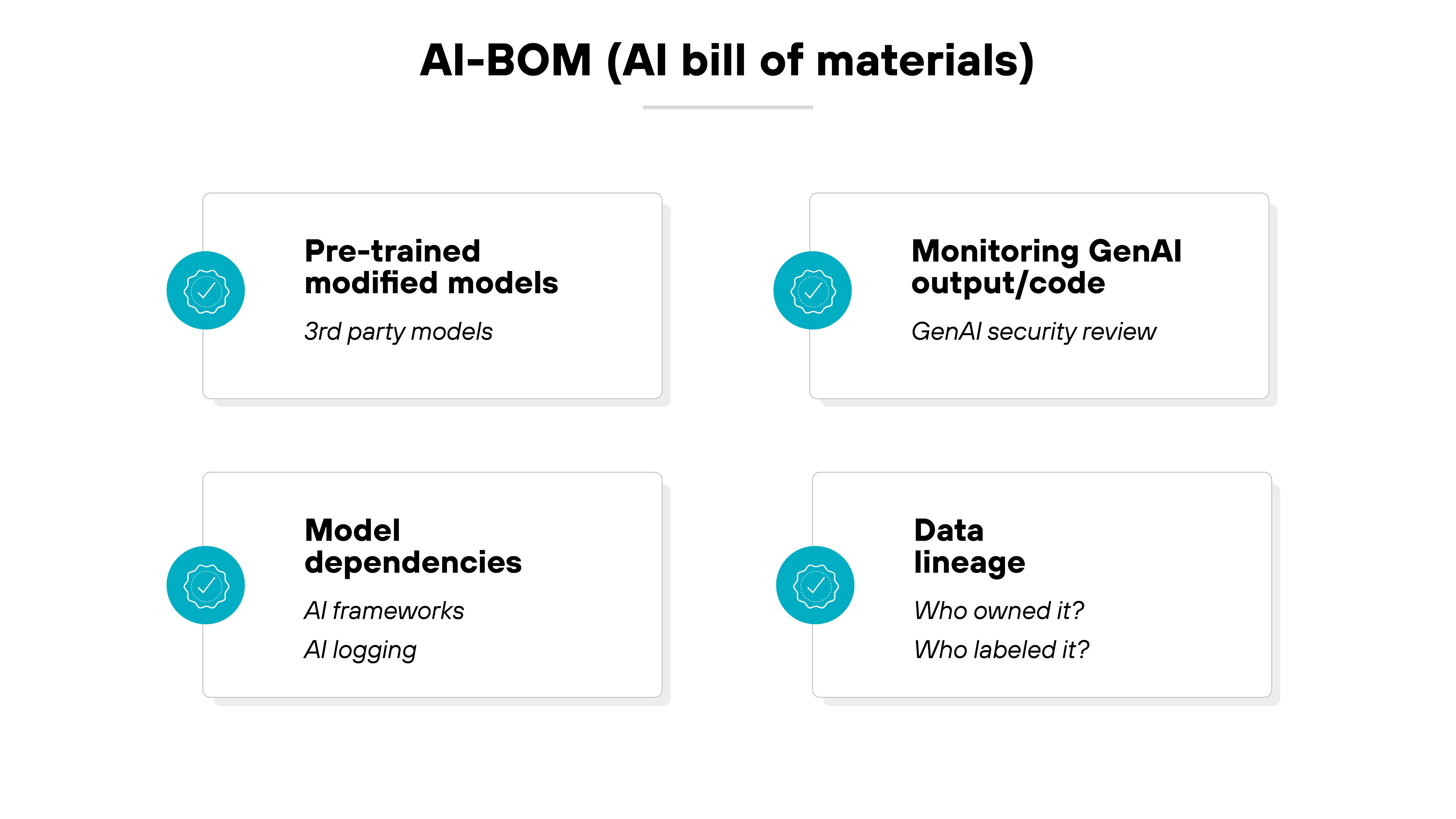
Maintaining a detailed AI-BOM ensures that only approved components are used. Which helps your organization manage risks associated with third-party vulnerabilities and software supply chain threats.
It also enhances transparency and helps in compliance with regulatory standards.
9. Employ input security and control
To prevent AI systems from being manipulated by harmful inputs, it's important to implement strong input validation and prompt sanitization.
By filtering and verifying data before processing, it’s much easier to avoid issues like data poisoning or prompt injection attacks.
This practice is critical for ensuring that only legitimate, safe inputs are fed into the system, maintaining the integrity of AI outputs.
Tip:
Test your input validation methods using adversarial prompts. This helps expose blind spots in your controls and confirms whether prompt sanitization is functioning as expected under real-world attack conditions.
10. Use RLHF and constitutional AI
Reinforcement learning with human feedback (RLHF) and constitutional AI are techniques that incorporate human oversight to improve AI model security.
RLHF allows AI systems to be fine-tuned based on human feedback, enhancing their ability to operate safely.
Constitutional AI, on the other hand, involves using separate AI models to evaluate and refine the outputs of the primary system. Which leads to greater robustness and security.
Tip:
Maintain version control and audit trails for human feedback used in RLHF. This not only improves traceability but also makes it easier to investigate regressions or unexpected behavior resulting from past tuning cycles.
11. Create a safe environment and protect against data loss
To safeguard sensitive data, create a secure environment for AI applications that limits data exposure.
By isolating confidential information in secure environments and employing encryption, you’ll be able to reduce the risk of data leaks.
A few tips for protecting against unauthorized data access:
- Implement access controls
- Use sandboxes
- Allow only authorized users to interact with sensitive AI systems
Tip:
Establish time-bound access windows for high-sensitivity data used in GenAI training or operations. This ensures that exposure is limited even if credentials are compromised or access controls fail.
12. Stay on top of new risks to AI models
The rapid evolution of generative AI introduces new security risks that organizations have to address constantly.
That’s what makes keeping up with emerging threats like prompt injection attacks, model hijacking, or adversarial attacks so crucial.
Regularly updating security protocols and staying informed about the latest vulnerabilities helps ensure that AI systems remain resilient against evolving threats.
Tip:
Join an AI-specific threat intelligence community or mailing list. These sources often flag new model vulnerabilities, proof-of-concept exploits, and threat actor tactics long before they show up in broader security feeds.
| Further reading: What Is Explainable AI (XAI)?

GenAI security involves protecting AI systems and the content they generate from misuse, unauthorized access, and harmful manipulation. It ensures that AI operates as intended and secures data, models, and outputs against evolving risks like data breaches or adversarial attacks.
GenAI risks include data poisoning, prompt injection attacks, model theft, AI-generated code vulnerabilities, and unintended disclosure of sensitive information. Additionally, biases in AI models and unauthorized use of AI tools (shadow AI) can pose significant security and compliance threats.
GenAI risks include data poisoning, prompt injection attacks, model theft, AI-generated code vulnerabilities, and unintended disclosure of sensitive information. Additionally, biases in AI models and unauthorized use of AI tools (shadow AI) can pose significant security and compliance threats.
Generative AI can be safe if managed properly, but without robust security measures, it presents risks such as data breaches, malicious inputs, and exploitation of model vulnerabilities. Implementing secure development practices and continuous monitoring helps mitigate these risks.
In banking, GenAI risks include data breaches, fraud, model manipulation, and the exposure of sensitive financial information. AI models might also introduce biases, impacting decision-making processes, or allow unauthorized access to banking systems through vulnerabilities in AI-powered applications.
The two main security risks of generative AI are prompt injection attacks, which manipulate AI outputs, and data poisoning, where attackers alter training data to influence the model’s behavior, leading to biased or erroneous outcomes.
GenAI has introduced new security challenges by providing advanced tools for attackers, such as automating malicious activities and evading traditional defenses. It has also highlighted the need for enhanced model protection, including securing AI-generated outputs and addressing vulnerabilities in AI systems.